30 juin 2021Valentin DURAND Développeur informatique en chef
Résumé Vous voulez extraire les codes HTML depuis une image mais n'arrivez pas à le faire? Ne vous vous inquiétez pas. Dans cet article, nous allons vous introduire quelques outils qui peuvent reconnaître et extraire les codes HTML depuis une image. Vous trouverez la résolution dans cet article.
HTML est appelé également Langage de balisage hypertexte, qui est une application sous la langage de balisage standard. La page composée avec HTML contient des éléments non-texte, y compris des images, des hyperliens, même des musiques et des programmes. En activant (en cliquant) sur un pointeur d’URL, le navigateur peut facilement obtenir une nouvelle page Web. C’est pourquoi HTML est largement utilisé.
On peut voir que des pages Web sont basées sur HTML. Des pages Web puissant peuvent être créées par HTML avec les techniques Web (telles que des langages de script, CGI, modules, etc.). Par conséquent, HTML est la base de la programmation Web, ce qui signifie que le World Wide Web est construit sur la base de l’hypertexte.
Maintenant vous connaissez ce que c’est HTML. Ensuite nous voyons comment extraire des codes HTML depuis une image.
2/ Comment extraire les codes HTML depuis une image?
Pour extraire les codes HTML depuis une image, vous pouvez utiliser la fonction OCR d’un logiciel professionnel. Voici la recommandation des logiciels avec la fonction OCR, qui peuvent vous aider à reconnaître et extraire des codes HTML depuis une image.
1. Renee PDF Aide
Qu’est-ce que c’est Renee PDF Aide?
Renee PDF Aide est un logiciel polyvalent conçu pour l’édition PDF et la conversion du format PDF. Par ailleurs, ce logiciel intègre la technologie avancée OCR et peut convertir le document PDF scanné en Word, Excel, PowerPoint, Image, HTML, TXT et d’autres formats de fichier courant. En plus, vous pouvez convertir tout le document PDF ou une certaine page d’un document PDF en d’autres formats. La vitesse de conversion peut atteindre à 80 pages par minute. L’opération est davantage simple. Et aussi, les fonctionnalités d’édition permettent de réparer le fichier endommagé, d’optimiser le temps de chargement du fichier volumineux, de diviser un fichier, de fusionner des pages spécifiées à un document PDF, de modifier l’angle d’affichage du fichier, de chiffrer ou déchiffrer un document PDF et d’ajouter un filigrane dans un fichier.
En outre, Renee PDF Aide supporte la conversion du fichier PDF en français, anglais, allemand, italien, portugais, espagnol, chinois, coréen, japonais, etc. Sous le mode OCR, il suffit de sélectionner la langue du document PDF pour augmenter le taux de reconnaissance des caractères et l’efficacité de conversion. Les débutants de l’ordinateur peuvent utiliser Renee PDF Aide sans problème.
Renee PDF Aide – Editeur PDF polyvalent
Simple à utiliser Les débutants peuvent modifier un document PDF rapidement.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
Haute sécurité Chiffrer le fichier PDF avec l’algorithme de chiffrement AES256.
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/etc.
Simple à utiliser Les débutants peuvent modifier un document PDF rapidement.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
Haute sécurité Chiffrer le fichier PDF avec l’algorithme de chiffrement AES256.
Comment extraire les codes HTML depuis une image avec Renee PDF Aide?
Renee PDF Aide contient deux fonctions, « Outils PDF » et « Conversion PDF ». La première fonction consiste à éditer des fichiers PDF et la seconde à convertir un PDF en formats courants. Voici comment utiliser la fonction OCR pour extraire les codes HTML depuis une image.
Les étapes sont très simples:
Étape 1 : Téléchargez et installez Renee PDF Aide, puis ouvrez le logiciel et sélectionnez « Conversion PDF ».
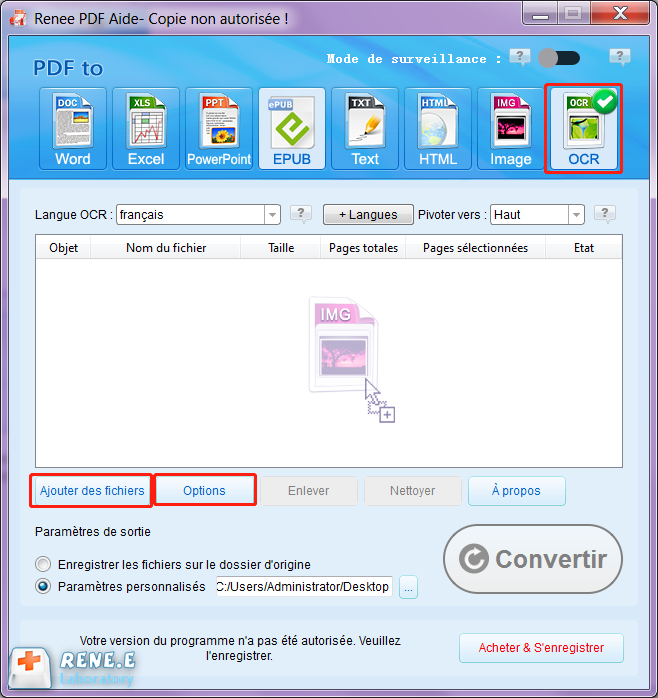
Étape 2 : Entrez dans l’interface de conversion et cliquez sur « OCR » dans le menu en haut. Puis cliquez sur « Ajouter des fichiers » pour charger le fichier d’image dont vous allez extraire les codes HTML (au format JPG/PNG/BMP) dans le logiciel.
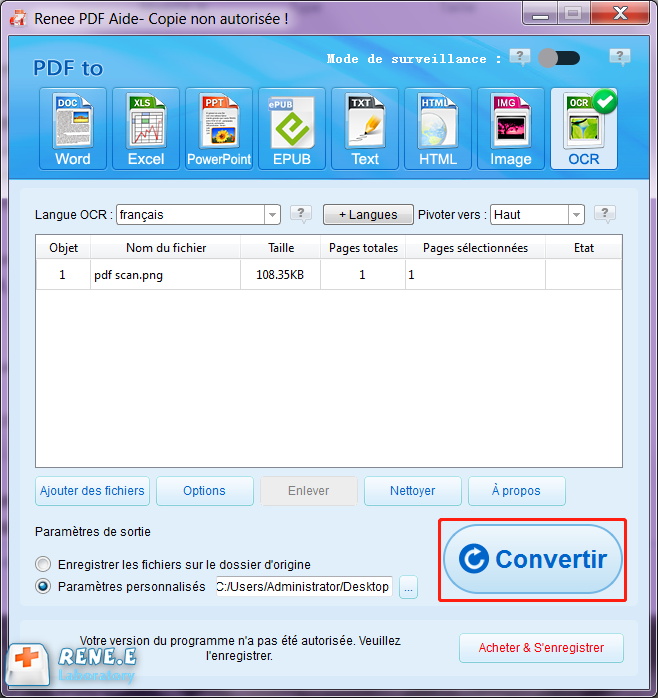
Étape 3 : Après le réglage, cliquez sur le bouton « Convertir » en bas à droite pour lancer l’extraction du code HTML depuis le fichier image et enregistrez-le en tant que fichier texte en TXT. Puis changez directement le suffixe du fichier « .txt » en « .html » pour obtenir un fichier HTML.
2. Google Docs
Google Docs est un convertisseur de format en ligne gratuit avec la fonction de l’OCR. Il peut réaliser la reconnaissance de texte de contenu d’image ou de fichiers PDF. Voici comment utiliser Google Docs pour reconnaître et extraire le code HTML depuis l’image.
Voici les étapes:
Étape 1 : Connectez-vous à Google Drive avec votre compte Google. Puis trouvez « My Drive » – « Upload files » pour importer le fichier d’image à Google Drive.
Étape 2 : Faites un clic droit sur l’image téléchargé, puis sélectionnez « Open with » – « Google Docs ». À ce moment-là, une icône de feuille de calcul apparaîtra lors du chargement du fichier, ce qui signifie que Google utilise la technologie OCR pour reconnaître votre fichier image.
Étape 3: Une fois le fichier modifié, recherchez « File » – « Download » dans le menu des fonctions et sélectionnez « HTML » comme le format de sortie. Puis les codes HTML seront enregistré en texte à l’emplacement prédéfini sur votre ordinateur.
3. FreeFileConvert
FreeFileConvert est un convertisseur de format en ligne multifonctionnel et gratuit. Il dispose d’une variété d’outils des formats multimédia, tels que le convertisseur audio/vidéo/image, le convertisseur de fichier et de livres électroniques, le convertisseur de polices et le convertisseur d’unités de mesure, etc.. De plus, il offre les fonctions d’édition pour le fichier PDF, comme la compression, la division, le cryptage et le décryptage, etc.. Par rapport aux autres convertisseurs de format en ligne, FreeFileConvert dispose d’une fonction OCR qui peut améliorer la précision du contenu lors de la conversion de format. Voici comment utiliser cet outil en ligne pour extraire le code HTML de l’image.
Voici les étapes:
Ouvrez l’URL de FreeFileConvert dans votre navigateur: https://www.freefileconvert.com/jpg-html. Puis cliquez sur « Choisir un fichier » dans « Input File » pour importer l’image cible (Remarque : cet outil peut convertir chaque fois cinq fichiers au maximum, et la taille maximale du fichier ne dépasse pas 300 Mo). Puis choisissez « HTML » sur « Convert File to » dans la colonne « Output Format ». Une fois configuré, cliquez sur « Convert » pour lancer la conversion de l’image en fichier HTML.
3/ Conclusions
Nous avons présenté trois outils pouvant reconnaître et extraire les codes HTML depuis l’image. Voici la conclusions et nous vous espérons que ça peut vous aider.
En terme de la fonctionnalité:
Tous les trois outils disposent de la technologie OCR qui est pratique et efficace lors de l’extraction. Mais il existe des différence en terme de leurs fonctionnalités. Le fonctionnement de Renee PDF Aide est plus stable que les deux autres outils, et il peut fonctionner hors ligne sans causer l’interruption de l’extraction des codes HTML. De plus, Renee PDF Aide prend également en charge la conversion et l’édition du fichier PDF.
En terme de la sécurité:
FreeFileConvert et Google Docs sont les deux outils de conversion en ligne. Vous devez télécharger les fichiers d’image sur le serveur en ligne et il existe des risques de sécurité. Bien que Google Docs soit développé par Google et la sécurité des données sont garantie, il est moins sûr que Renee PDF Aide car les fonctionnements du logiciel seront terminés dans le PC local, les données ne risquent pas d’être divulguées.
En terme du résultat de la conversion:
Renee PDF Aide utilise la technologie OCR plus avancée, qui prend en charge de la reconnaissance multilingue et l’effet de la conversion sera mieux. Bien que Google Docs et Free File Convert disposent de la technologie OCR, les fichiers ouverts via Google Docs ne conserveront que le texte du fichier sans style d’origine. Si vous devez conserver la mise en page d’origine, c’est mieux d’utiliser les deux autres outils. Comme FreeFileConvert prend en charge moins de langues OCR, si vous devez extraire le texte multilingue, ce logiciel est moins efficace.
Selon les analyses ci-dessus, vous pouvez choisir ce que vous désiré selon vos besoins actuels.